At Freelock, we've been adopting a pattern for git branch management called Git Flow. If you haven't run across git flow before, go check out this article to get the basic concepts: A successful Git branching model.
Git Flow provides a handy tool for creating release, feature, and hotfix branches and keeping them organized. However, it (and most other software code management strategies we've run across) are organized around managing software releases. When you apply them to a Drupal development process that involves deployment across several server instances, it's not quite sufficient by itself.
It's fine to keep production on a master branch, but we find that a single "develop" branch is nowhere near sufficient to accommodate our actual needs. Here's an example:
We start on a sprint for a client, to add some entirely new functionality to an existing site. As we near the end of the sprint, we learn that they don't really want the data displays visible to the public -- but they need to start collecting the data now. So we want to push some features up to production, but not the rest. If we finish our features as we go, the "develop" branch has ended up with everything we want to get pushed up, and now we need to extract and revert the commits involving the features they did not want. And figure out how to re-revert them later.
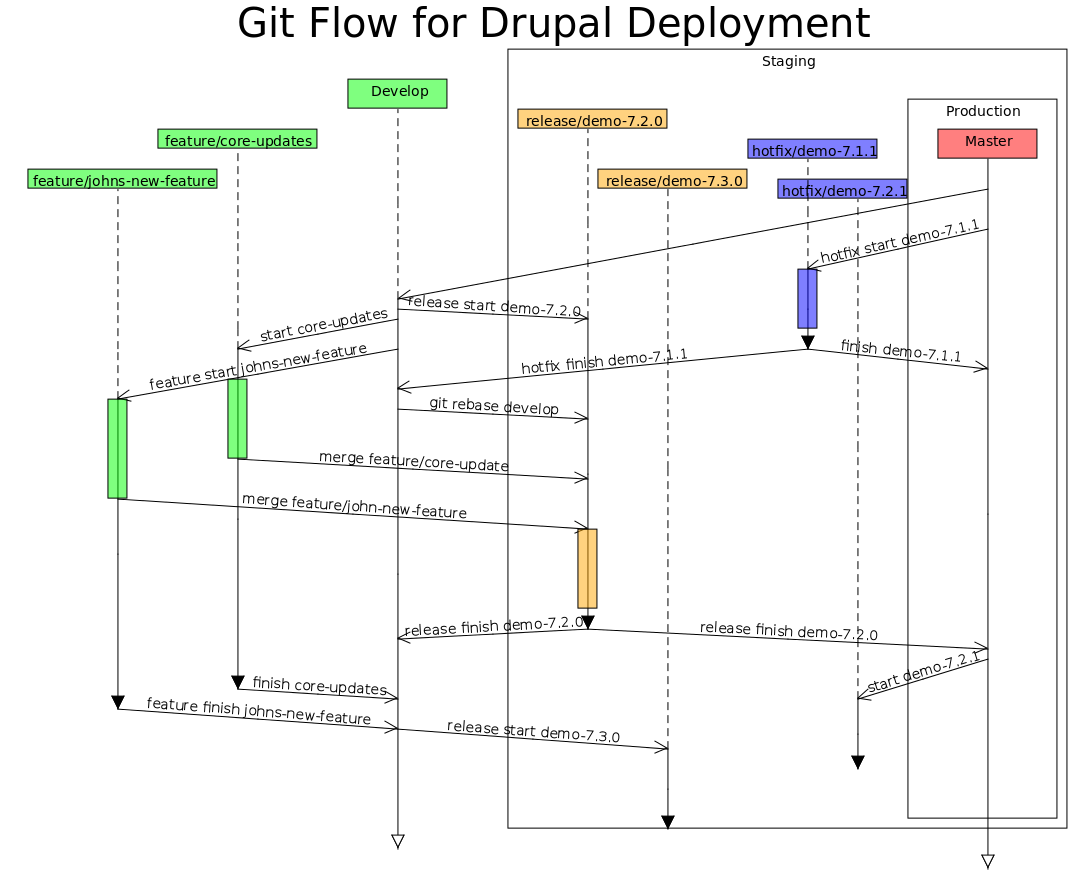 So our biggest changes over the regular git flow strategy is to leave feature branches open until after they have been released, and use release branches as integration branches in preparation for a release. Click on the diagram to see the big picture...
So our biggest changes over the regular git flow strategy is to leave feature branches open until after they have been released, and use release branches as integration branches in preparation for a release. Click on the diagram to see the big picture...
We're still working out the kinks, but having a consistent way of organizing our site copies has been an important step.
The git flow diagram illustrates primarily how we use branches within each repository.
Site instances
To add to the complexity, we may have up to 5 copies of the site code that we're managing:
- Central master git repository, no site instance
- Production site instance
- Staging site instance
- Development site instance
- Local development copy
We use the central git repository much like you would use a Subversion server, or any other centralized code repository -- it's considered the authoritative copy of all work. As a bare repository, you have to resolve any merge conflicts before it will allow you to commit any code.
The production site is easy -- it's on master, it stays on master, the only reason it should never not be on master is if we have to roll back to a previous release tag, if something truly went wrong.
Staging is where things get interesting. The staging copy of the site might be on any of the branches in its box in the diagram above -- it might be on master, a release branch, or a hotfix branch. Its main purpose is actually to test deployment -- given that deployment in Drupal (at least before Drupal 8) is not a straightforward task.
Development is where we integrate the work done by multiple developers, and do most of our integration testing.
And if there are multiple developers on a project, they will often each run their own local development copy.
Recipes
This branching strategy supports most of the deployment scenarios we run across. And while I can go into a lot of detail about why we've adopted this strategy, today I'm going to skip all that and get straight to the nuts and bolts: what steps do we take when starting a new project, taking over an existing site, getting a new work request, applying module updates, do work, or releasing a sprint?
Starting a new project
Yahoo! We don't often get to start completely fresh! So first off, celebrate! Now let's get to work:
- Create a new repo in our central repository.
- Create a development site, and merge in our Drupal-Base repository as a remote called "upstream" (this is a repository that tracks the main Drupal git repository, with branches that include modules we use on many sites).
- Push the master branch into the central repository.
- Initialize git flow with "git flow init", setting up the master and develop branches.
- Run through the Drupal installation with an appropriate install profile to create the initial database.
- Continue on with New Work Request, below...
... and we're off and running!
Taking over an existing site
Most of our work comes from clients who already have a site up and running, developed by somebody else. Often these sites have no version control, or little branch management if there is. If it already uses git with branches, we might have to modify or adapt to the desired conventions of the site, but when the decisions are up to us, here's how we proceed:
- In their production instance, "git init" to create a git repository. Add appropriate .gitignore entries, and commit all code to master, ignoring all assets.
- Copy the settings.php file to production.settings.php and commit. Create an ignored symlink to it to replace the settings.php file, and make sure that settings symlink is ignored.
- Create a central repository for the site, and push the production site into it.
- Create a development instance from the central repository, add a development.settings.php file, and get up and running.
- Determine what changes need to be made when updating a development db from production, and create script to automatically apply. For example, disable securepages, enable/configure reroute_email, enable test payment gateway and set as default, set Apache Solr search index to Read Only, etc.
- Continue on with the New Work Request, below... one of the first sprints should be to merge our upstream repository and apply updates in an early release.
New Work Request
This is our core triage, with a number of decision points/questions to ask. The key technical decision points are:
- Is there an active sprint for this client?
- Is this work going into a sprint, or is this a one-off request?
The answers to these questions affect whether we're going to create a release branch or a hotfix branch, and what version number we'll give it.
Our version numbers consist of a project short name, the Drupal major version number, the sprint number we're on for that client, and a "hotfix" number. For example, we have a "freelock-7.3.2" version for this site, on Drupal 7, the 3rd sprint, and the second minor (hotfix) release since the beginning of that sprint.
If there is no active sprint for this client, and if this work is not going into a new sprint but just a one-off request, we create a new release with a bump to the hotfix number. Here's the git flow command:
git flow release start freelock-7.3.3
This creates a release/freelock-7.3.3 branch from the "develop" branch (you don't have to switch to that first, it does it for you).
If there is an active sprint for this client, and this is a one-off request not going into that sprint, we use a hotfix to slipstream it past the rest of the development:
git flow hotfix start freelock-7.3.3
... which creates a hotfix/freelock-7.3.3 branch.
If the work is going into the active sprint, you don't need to create any new release or hotfix branch.
If there is not an active sprint, but we're going to create one, there's a bunch of project management work to do first. That would include bumping the sprint number, so when that plan is complete, we'd start the release branch with:
git flow release start freelock-7.4.0
It really does not matter which instance of the site you create these on -- as long as it's not production, and as long as you push the result into the central repository.
The other thing that must happen when starting a new release: get a fresh copy of the production database imported on all relevant instances. The only exception is if there are unreleased features -- in that case, it's best to keep at least one instance running with those features configured and running.
Apply module updates
When applying module updates, we follow the same general triage process as any New Request, except we're the ones making the call on whether to include in a sprint or not. So the decision script is slightly different:
- Is there a critical security update for this site?
- Is this a high risk vulnerability? (The vast majority of Drupal security updates fix vulnerabilities that can only be exploited by users you've already given some level of administrative access to, and we consider not risky).
- Does the client have a sprint coming up?
If you're on one of our maintenance plans, we do rush out truly critical security updates, or at least make sure that your site is not at risk. If the site has any current work going on, this is exactly what a hotfix is for -- to slipstream an important update out to production, bypassing other development work.
git flow hotfix start freelock-7.3.3
work ... work
test ... test
... bump version number in production.settings.php
git flow hotfix finish freelock-7.3.3
git checkout release/freelock-7.4.0
git rebase develop
If it's not a high risk vulnerability, we will check to see when your next sprint is planned. If we're in the midst of it, we'll apply the updates on a new feature branch, and merge them into the release branch for testing.
git flow feature start ctools-update
work ... work
test ... test
git checkout release/freelock-7.4.0
git merge --no-ff feature/ctools-update
If we have a sprint coming up (we generally try to apply all updates the week before your sprint starts), we will review all module updates, and we will generally apply them all on a new feature branch. In this case, after doing some light testing on the feature branch, we will usually go ahead and finish the feature so that everybody doing development during the sprint can find any resulting problems that arise out of the updates.
git flow feature start ctools-update
work ... work
test ... test
git flow feature finish ctools-update
If we don't have a sprint planned, we'll create a new release branch, apply the updates, and do our normal "new work request" process.
Do Work
Ok, here's where developers start caring: what do they need to do, day to day, to get their job done?
The first key decision is when to create a new feature, and where across all the various site copies to do the work. Here's a quick decision matrix:
| If | Use |
|---|---|
|
Main development instance or local development instance |
|
Local development instance |
|
Production instance (be sure to pull database down to staging for extensive testing) |
Try to group related functionality together into the same feature branch. In general, if you're working with another developer on a set of functionality, you will need to work in the same instance.
Each instance with active development going on must be on its own branch -- otherwise merging gets difficult.
If there's any chance the client will want to split functionality into different releases, try to anticipate those places and put them in different feature branches. You can merge one feature into another.
Create new feature branch:
git flow feature start cool-ecommerce-enhancement
... work
git commit
git flow feature publish cool-ecommerce-enhancement
git push
Create new feature branch that depends on another branch
git flow feature start cool-ecommerce-reports
git merge --no-ff feature/cool-ecommerce-enhancement
... work
git commit
git flow feature publish cool-ecommerce-enhancement
git push
Both of the above scenarios can be done on a local or main development copy. Publishing the feature makes it get pushed up to the central repository, where others can access it and merge into their own features or into a release. Be sure to commit and push regularly.
Release a sprint
So far, so good. We've talked about how to create branches, do work, do all the setup. What about getting it out the door?
If it's a green development site, no production or staging yet, release is pretty straightforward: do the merges and finish the release, copy the site up to the production server, and run down the launch checklist.
If a production site already exists, that's when we need a staging copy -- to test whether the deployment breaks anything. And this is where Drupal greatly complicates things, by storing so much structure in the database. Here's the rough outline:
- Switch to the release branch, and merge in what's going into the release:
git checkout release/freelock-7.4.0
git merge --no-ff feature/cool-ecommerce-enhancement
git merge --no-ff feature/ctools-update
git merge --no-ff feature/cool-ecommerce-reports
(bump version number)
git commit
git push origin release-7.4.0
- Check out the release branch on the Staging instance of the site. (We're working on getting Jenkins to handle these next few steps...)
- Copy down a fresh copy of the production database to staging, and apply the environment module changes.
- Run all database update scripts
- Run down the sprint deployment list and apply
- Turn over to QA for testing
- Notify customer for acceptance testing
- On approval, finish the release:
git flow release finish freelock-7.4.0
git push origin master
That takes care of the code release! Next it's a matter of doing the production deployment:
- Tag current production code commit
- Back up current production database
- Take site offline if deployment is more than a few minutes
- git pull
- drush updatedb
- Run down the deployment list and apply, marking each item released as it's finished
- Final smoke test
- Put site back online
Last, finish up all the features that were merged into the release:
git flow feature finish cool-ecommerce-enhancement
git flow feature finish cool-ecommerce-reports
git flow feature finish ctools-update
... and that's it!
... ok, not quite. There's a lot more tricks up our sleeves, things we're doing or planning to make this work easier, including:
- Scripts for rapidly creating new site instances
- Scripts for database copies/updates from production, along with environment changes appropriate to dev versus production instances
- Continuous Integration, automated testing
- Drupal features








Comments
Database handling
Would love more detail on how you handle versioning of the database. Do you make the client stop adding new content to the production site when making updates that affect the database or do you somehow merge the changes? Or if one developer is building a feature and another developer building a different feature, both install different modules to their branches, how are the different databases merged together?
We don't version the database
We don't version the database, and once a site is in production, we never, ever copy a dev or staging database up. We do back up the database immediately before deploying code changes, and tag the codebase.
Testing deployment is the most critical part of having a staging site instance. So our process for any major deployment looks like this:
If the deployment involves a lot of manual steps, and the site looks bad or could lead to serious issues if used during deployment, we will set the site offline while we're deploying. Generally we try to avoid that, however, and allow users to keep using the site during deployment.
So in short, code moves from dev to staging to production, while databases move from production to staging to dev. Database changes need to get re-played when moving the other direction -- we do not allow copying databases out to production unless the site has not yet launched.
We're really looking forward to Drupal 8's much improved deployment features!
Great info. So how would
Great info. So how would handle this type of situation, two developers are working locally on a site, each installs a different module on their local installation. How would you handle the database differences between them? Do they both work off the same remote database (in that case do they get errors because they don't have the module the other one installed)?
Basically how do multiple people work on the same Drupal site where local installations will be different until merging (specifically the database)?
I apologize if these are dumb questions, my company is just starting to fully utilize this type of workflow.
In our environment, each site
In our environment, each site copy has its own database.
If different modules are deployed in different instances, it's up to the developer to provide deployment instructions when merging into a company-wide development copy, so that they can be done during deployments to staging and production.
Something like enabling a module can easily be done by adding it as a dependency to a feature or custom module, or enabling in a hook_update_N function if appropriate.
Deployment like this does take planning, and we've definitely had lack of deployment plans come back to bite us. That's part of why I wrote this post -- to establish our standard practices. We've added deployment instructions to our project management system, and made completing those part of the "development complete" step for each case.
But that is one benefit of having so many copies -- it gives the developers a chance to test out deployment in a safe environment where you're not breaking production.
Using bash + drush to deploy
RE: "up to the developer to provide deployment instructions "
One thing I've done recently is create a bash script that runs a bunch of drush commands. I find most of what I'm likely to do at the config level is going to be turning modules on or off and changing variables in the variable table. Since this is built into drush, you can create a bash script that is just several lines of "en" and "variable_set" drush commands. If I track it while I go, I can deploy with less chance for error as long as dev/test/live all have drush installed and similar paths.
Hi, Tom,
Hi, Tom,
Thanks for commenting. We've taken a similar approach, but a step further -- automating the database copy from production down to staging and development machines, and then enabling/disabling modules and changing settings to make them safe to run on development/staging copies.
We haven't quite figured out how best to manage some of the site-specific things, but that's next -- changing the credit card gateway to the test gateway only on Ubercart sites, setting Apache Solr to read-only, etc. But it's getting better all the time! And right after that, we're going to hook up Jenkins to watch particular branches, handle deployments to a staging copy when we push a release or hotfix branch, and deploy to production when we push to master.
Environment?
A couple of thoughts, one that I have used and one that I have not.
1. Namespace-specific includes in the settings.php file (so settings-local.php, for example) that let's you change the DB settings or whatever and also lets you set conf variables.
2. The Environment module which I haven't tried, just heard about (MortenDK recommended it in a conversation on this subject at BADCamp). Have you tried it?
We've tried both
Well, partially anyway. Rather than doing separate includes in the settings file, we do entirely separate settings files, and then use a symlink to point to the one we want.
We add that symlink to the .gitignore, and it then can point to a production-settings.php or development-settings.php or any number of other variations we might need for different environments. While at it, we have environment_indicator settings there, and a couple other things as well.
I played around with the environment module a while back, and created some hooks to see how it works. But I did not really like keeping that active in production -- which is necessary if you want it to be active when you copy down the production database. So we're going more for the script approach.
But putting some settings in the appropriate settings.php file that we can leverage from the script to determine what needs to change when we switch environments, that might be what we end up doing. Or enabling environment module for a site copy, applying the environment, and then shutting it off again.
prod on a tag on master but not HEAD
We are looking at gitflow and aegir boa also
A devops session at badcamp 2014 covers this
Acquia cloud got us using a tag of master on prod
Updates to the process?
Great write up - I'm wondering if you are still using the same exact process or have found ways to improve it further?
Add new comment