
How do you get a website back up, when it goes down?
Availability is one part of the security triad - a useful way of assessing the security of a site. When we talk about security, it's often about the other two parts -- confidentiality (keeping secrets safe), or integrity (making sure your data is intact and not corrupted).
The strange thing about availability is that it's the hardest part to get right -- and yet in many cases the least consequential. If you have a data breach and expose customer data, that could end your business. If your data gets corrupted, that could lead to hidden errors and worthless systems. But if your site goes down, is it really that bad?
It could be... but the answer is, like everything else in tech, "it depends."
Let's dig into why a website might be unavailable, and what steps we take to deal with an outage.
What makes a website available?
A typical Drupal site depends on a stack of software, systems, and hardware. A failure on any layer of that stack can lead to an outage. So the more layers you have, the more things can take your website down. Diagnosing an outage starts with identifying which layer or system is causing the outage. Let's start at the top, and we'll get more technical as we drill down.
The top of the stack - DNS
The "Domain Name System" (DNS) is the phone book of the Internet. Your browser uses DNS to get the IP address of a website, so it knows where to connect to load your site. DNS for most sites involves a couple different things that might cause an outage: Domain Registration, or your name servers.
If there is a DNS issue, you will usually get timeouts, "domain not found" errors, or landing pages that are trying to sell you a domain. A good quick test is trying to "ping" the domain name that's failing -- if you get a "Name or service not known" response, it's probably a DNS issue.
Cause 1 - Expired or misconfigured domain registration
This happens more often than you would think! Domains are registered for years at a time, so often by the time a renewal comes along, the previous credit card has expired or is no longer valid, or the person who paid for it previously is no longer with the company.
To diagnose an expired domain, "whois" is the tool. It's easily installed on any Linux system, and it will tell you who has registered a site and when the domain expires. When a domain expires, it basically disappears off the Internet -- nobody will be able to reach it anymore. It does stay available in "Whois" for approximately 120 days after it expires, before it gets fully released so someone else can buy it.
If the domain has expired, the only solution is to have the site owner renew it. After they do so, everything generally comes up within a half-hour or so.
Cause 2 - Name Servers
The domain registration points to two or more "name servers" that provide the actual addresses for a website. So after checking "whois", the next step is making sure the name servers are running and providing the address for the website. "dig" is the tool for this -- short for "domain information groper". You use it to grope mail servers and coerce information out of them.
The quick test is simply to use dig on the domain name:
❯ dig freelock.com
; <<>> DiG 9.20.9 <<>> freelock.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27745
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 13
;; QUESTION SECTION:
;freelock.com. IN A
;; ANSWER SECTION:
freelock.com. 600 IN A 104.197.151.58
;; AUTHORITY SECTION:
. 43465 IN NS e.root-servers.net.
<snip>... this tells us that freelock.com is at 104.197.151.58, and you can cache this information for 10 minutes (600 seconds).
This is the "A" record for the domain. There are other kinds of DNS records you can look up if you think DNS is a problem -- if some people can't reach the site while others can, it might be a problem on one name server and not another -- there should always be at least 2, but if they are not in sync, this can cause problems.
With dig, you can specify a record type to retrieve by adding it to the end -- e.g. dig freelock.com ns will return the name servers for the domain -- you can verify whether they are the same name servers as in the domain registration (the whois record), and then test each name server to make sure it's returning the expected A record using dig: dig @ns1.freelock.com freelock.com.
If all the nameservers return the expected IP address, it's probably not a DNS issue.
Delivering traffic to your site - Routing issues
The next layer to consider, after DNS, is routing. Now that your browser knows what IP address your site is on, can traffic reach it?
Again, "ping" is the quick test -- can you ping the IP address for your site? If the site is available for some people but not others, can the people who cannot reach it ping the IP address?
Cause 3 - Network issues
Networking is a complex topic all on its own. For dealing with a website availability issues, if it's a network issue, the first step would be to narrow down where the problem is -- is it on a particular network or LAN? Is it at the host? Or is it somewhere in between?
Many organizations have their own internal network, and this often includes their own internal DNS servers. So if a client can't connect to a website but the rest of the world can, it's probably a problem with their network, and not actually anything to do with the site.
On the other hand, there could be a problem inside the datacenter where the website is hosted. These are usually maintenance related issues, and most hosts have multiple checks to prevent this from happening -- but they are people and do make mistakes. If nobody can reach the site at all, check the status page for the web host to see if there are any known outages, and if not, file a ticket.
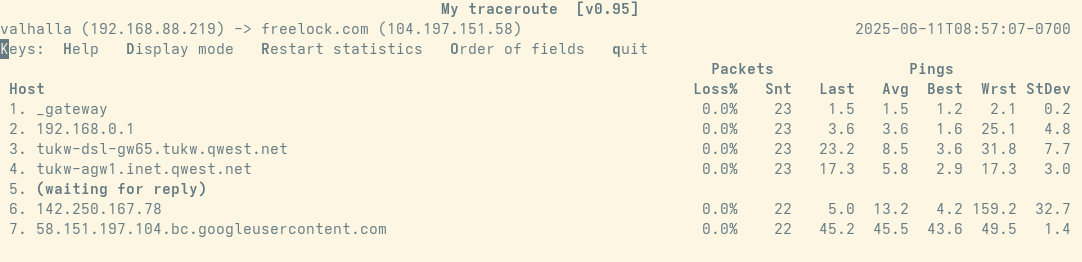
To narrow down the source of the problem, you can use tools like traceroute, tracert, mtr ("my trace route"). These tools test each "hop" traffic makes between you and the remote website. Each "hop" is a router directing traffic to the next "hop" in the chain. Occasionally a major Internet routing layer has a problem -- traffic is supposed to route around the problem, but this doesn't always happen -- things sometimes fail.
Some routers don't respond to ping, but if you see a response from a later server that's not necessarily an issue -- the packet loss percentage is the most important part of this display -- if packets are lost at a certain hop, that's where the problem is. And to resolve it, enlist your web host to work with their providers to fix the issue (or change the routing).
Fix - diagnose from the host (server)
If it's a problem with routing to the actual server, there may be something on the host itself causing the issue -- perhaps some critical part of the network stack got killed. If you can't log in through the network, you can usually go to the web host's control panel and open a "Recovery Console" on the server itself. This opens a screen to the virtual host, as if you had plugged in a keyboard and monitor. You can use tools like curl and dig on the server to see if it can see the outside world, and if not, take appropriate steps.
Hardware issues
If you can get right up to the host but you cannot ping it or connect on any port, and cannot use the recovery console, it might be a hardware issue on the server itself. You might need to test from an internal IP address to get through any firewalls blocking access from the Internet at large -- we typically do allow pings through firewalls from the greater Internet, but not SSH connections -- and many of our clients block pings. So it's not a conclusive thing if you cannot connect to a particular server.
We do make sure firewalls allow access from our main LAN, so our team members can connect using a VPN or hopping through a dev server (using a "bastion" host).
Cause 4 - Hardware issues
That said, if we cannot connect to a host (server) at all, we need to check with the web host for next steps. For managed hosts, the main thing we can do is open a ticket. Some do have chat or phone support, so these are resources to we can use.
Most of the web hosts we use do provide tools for self-service. We almost always provision servers as "Virtual Private Servers", and hardware portability is one of the biggest benefits.
Fix - Move the VPS to new hardware
Most hosting providers we use automatically migrates to new hardware after a full shutdown of a VPS. So if it's a hardware problem, we log into the control panel for the hosting service, and attempt to shut down the host. As of spring 2025, we haven't had to do this for a couple years -- but it used to be something we would need to do 2 or 3 times a year across the fleet of servers we manage.
Before doing this, try a simple restart of the server. That won't move it to new hardware, but if the server is hung, that doesn't necessarily mean there's a hardware issue. If a reboot works, even if only for a minute or two, it's probably not a hardware issue.
If not, stop the server in the host's control panel. You do need to be patient with this -- it can often take 20 - 30 minutes to fully shut down a host that's having issues. For AWS, I typically use the "Force Stop" after waiting a few minutes after a normal stop. Be sure to not use the "Terminate" option, which deletes the host entirely!
Once the host has fully stopped, you can usually start it again and everything should come right up!
Fix - Restore from backups
If you cannot get it to come up from the host's control panel, it may be time to restore from a backup.
You have backups, right?
We always configure snapshot backups provided by whatever web host the site uses, so we can recover quickly. As long as this is available, and the web host itself doesn't have an underlying issue, recovery is generally pretty straightforward. The exact steps vary from web host to web host, but typically it's along these lines:
- Create a new VPS instance based on the most recent nightly snapshot.
- If the server uses additional disks for data, provision a new disk based on the data snapshot.
- Log in to the new server and configure the correct disk mounts, and restart.
- Change the IP address ("elastic IP", "reserved IP") for the site to attach to the new server - or if you don't have one, update DNS to point to the new server.
That's generally what's needed to restore from a backup kept on the same service. If for some reason you can no longer access the service, then recovery is a bit more convoluted, and you'll need to have a secondary backup available -- another thing we highly recommend!
Fix - Restore on new service
This is the last-ditch recovery if your entire web host disappears or is inaccessible for some reason. (It happens -- there have been datacenter fires that have taken entire companies offline for weeks!) Since this is a very rare thing that might happen, we tend to make sure it's possible to recover, but not necessarily that fast. The biggest hold-up is usually getting ahold of the backups.
We do provide a secondary backup service for clients that don't have their own backup systems, but most often we work with the internal IT people at our clients to make sure they are getting regular backups to cover this risk.
Restoring from a complete loss looks like this:
- Provision new hosting.
- Deploy a new server to the new hosting, using our standard server configurations (now using NixOS with DeployRS).
- Recover the backup database and user generated files on the new server.
- Update DNS to point to the new server.
Host issues
Congratulations! You've made it through the network and DNS successfully -- and narrowed the problem down to something on the host. Now we're getting to the complicated stuff. DNS issues tend to be related to the client. Network issues depend on a bunch of people who are not me. Now that we're on a host, it's our problem (if you've hired us for server and site maintenance). When we're on the host, there are a bunch of interconnected systems all at play, and all of them have a bunch of different ways they can fail or be attacked. Large or busy sites often add even more systems, which can actually make them more vulnerable as a result -- in this industry far too many people think throwing a load balancer will solve outage issues without considering the ramifications in terms of vulnerability, cost, latency, and effort.
So, to troubleshoot issues on the host, you need a basic understanding of each component, and how each can fail. A basic Drupal site relies on these things at a minimum:
- A host (aka a server), with an operating system -- typically some flavor of Linux
- A web server - typically Nginx or Apache, but there are several others
- A PHP runtime - usually php-fpm but sometimes mod_php (a module that runs inside Apache)
- A database - typically MySQL or MariaDB.
In addition to the basics, there are a bunch of other systems that might be involved:
- A load balancer/proxy server - sits in front of one or more web servers -- it's basically another web server, but it also might be caching pages
- Docker/containerization - a system to run software isolated from other software on the system -- we use this to run Nginx and other containers
- Container orchestration - Kubernetes, Salt, other systems used to manage deploying new containers
- Memory Caching system - Redis, Memcached, Elasticache -- a service that is often used to make logged in traffic much faster
- Search engine - Solr, ElasticSearch -- we often deploy these for advanced search
... and finally, you have the website itself -- in our example, Drupal.
For this post, we're going to assume that all of that stuff is running fine and configured correctly -- and focus on the kinds of issues we actually experience that leads to a loss of availability -- we'll group all those system issues under one item:
Cause 5 - Configuration or Application issue
Generally these are not the issues that cause middle-of-the night outages. They are things that happen when updates are applied or deployed.
The fix? Roll back whatever you just rolled out.
Can you do that?
For many, many places, the answer is no. If you don't meticulously track each update somehow, how are you going to find the right version to roll back to? If you don't have a manifest describing exactly what was running before you updated, how are you going to know? If you didn't create a backup immediately before deploying, you're almost certainly going to lose some data (and thus have an "Integrity" problem as well as an availability one).
For a long time, our answer has been Docker for the servers, Salt for orchestrating system/server deployments, Git for tracking site revisions, Drupal configuration management and nightly checks, and Concourse for deployments that ensure a backup and tag before each site deployment. Now we're adding Nix for server/host management, which is making it much easier to roll back if there's a problem.
Fix - Roll back a site
To roll back a site, we generally revert the commits in the git repository and re-deploy. If it is on one of our servers, we can also go to the site directory and simply check out the previous release's git tag, and import the configuration.
If this doesn't work due to schema changes in the database, we'll need to grab the database backup that Concourse created and import it -- which would lose any data added to the system since the deployment.
Fix - Roll back a container
If the issue has to do with one of the servers we run in containers -- Nginx, php-fpm, solr, redis, mariadb -- the fix is to update our container registry to have the known "good" version set as the latest image. This means pushing a previous image into it.
Where are the previous images? The quickest place to find them is on the production server -- docker images will show all the active or recent images, and you should see ones that were recently replaced. You can use docker to tag the previous image, and then docker push <imagename> back into the Freelock Docker registry. And then trigger a container redeployment -- salt-call state.sls docker.containers on our old servers, or systemctl restart docker-<containername>.service on our NixOS hosts.
Fix - Roll back a server configuration
Most of our older server configurations are managed and deployed through Salt. We do keep salt configurations in git, so we can revert changes to roll out previous configurations. With our newer NixOS servers, we can roll back not only configuration but also supporting software versions. Check out the nixos-config repository, check out a commit previous to whatever change broke things, and then deploy. If you don't have Nix on your local machine, this can be done on the production host with nixos-rebuild switch .#host.
Traffic/load issues
Most of the causes listed above rarely bring a site down. . They certainly can, and we do get hardware failures after hours -- but now we're getting to the things we do see a lot more often. Many of these can be handled by throwing a lot more money at the problem -- provisioning bigger servers, adding redundant servers, eliminating bottlenecks. These are things developers don't often deal with -- this is more the territory of DevOps, System Administrators, or the current job title: "Site Reliability Engineer" (SRE).
The causes below are all related to too much traffic. It might be malicious, intending to bring the site down. It might be natural, a post that went viral. It might be a side-effect -- for the past year we've seen A LOT of badly behaved AI bots crawling pages that make the entire site get bogged down.
Many people reach for CloudFlare to address these issues. CloudFlare can deal with a lot of these issues, and it's an excellent service -- but I think CloudFlare has gotten way too big. There have been several CloudFlare outages that have brought huge amounts of the Internet down, simply because so many sites use it.
The one scenario where I would recommend CloudFlare is if your site is controversial to the point that it's the target of repeated Distributed Denial of Service (DDoS) attacks -- CloudFlare is probably the best service to handle the largest scale attacks.
Short of that, I think we've been able to field and deal with all the lesser traffic scenarios we've run across using open source tools we already have available.
Cause 6 - Simple Denial of Service (DOS) Attack
I tend to think of DOS attacks as "slow" or "fast". Nearly all the attacks we see are "slow" attacks -- it's a moderate amount of traffic to a route on your website that can't be cached and consumes a lot of server resources to deliver. Search pages, or pages with "pagers" and hundreds or thousands of results are prime targets.
A "Simple" DOS attack is a stream of traffic from a single IP address that brings down your site. I don't necessarily care about whether a DOS is due to a malicious attack or some misconfiguration -- from my point of view, if it's traffic from one IP address that's bringing down the site, it's a "Denial of Service."
Fix - Block an IP Address
This kind of attack is "simple" because if it's from a single source, it's really easy to block. There are several places you can do this:
- Using Drupal core's "ban" module
- Adding a firewall deny rule in the hosting service, or a front-end layer like CloudFlare
- On our Docker-based servers, add a firewall rule using IPTables:
sudo iptables -I DOCKER-USER 1 -s 34.46.27.91/32 -j DROP
The trickier part is to identify the source. There are log aggregation and analysis tools that can be a huge help here. Even without any other service, Linux shell tools like awk and grep can really help you identify where traffic is coming from. Here's a typical pipeline I use for analysis:
cat /var/log/nginx/freelock.com-access.log | grep "search\?" | awk '{print $1}' | sort | uniq -c | sort -n... that command will take all the rows that contain the string "search?" (which might be leading to a "slow" attack I'm seeing in the logs), printing the first field of the log (which is the source IP address), sorting those and counting the number of hits from each IP address, and then giving you the list of all IP addresses in increasing order of the number of times they've hit your site.
If you see an IP address in this list that's hit thousands or tens of thousands of times, it might be the source of the attack -- but make sure it's not one of our monitors.
Cause 7 - Unruly crawlers
This has been the number 1 cause of availability issues we've been seeing for the past couple years. Most of the recent ones come from AI companies, but there's plenty of others related to SEO, social media, and more. We dealt with a lot of them during spring 2024, but our fix stemmed the tide for nearly a year. Recently we've had some new ones appear, and more aggressive searching as agents come online that do live searches.
Fix - Rate limiting
I wrote a blog post about this a while back. We now have an Nginx config with a list of bots we've needed to slow down. By using log analysis techniques, when a new one shows up and causes trouble, we can simply add the user agent string to our list, and then Nginx simply sends them a "429" error if they try to visit more than 6 times per minute.
You can also tell bots how often they can crawl your site by adding a special entry to the Robots.txt file -- but this is basically just asking them to not crawl so often, whereas the Nginx fix shuts them down.
Cause 8 - Slow DDoS
These are the hardest attacks to block, and we are seeing them more often. We can't deal with a "Fast" DDoS attack, because that's flooding your IP address with so much traffic the network can't keep up -- but that level of attack is extremely expensive, takes a botnet of hundreds or thousands of hosts actively attacking your site. This is the realm of cyber mafias and state actors, where there is a strong motive to bring you down -- or a bored script kiddie with a botnet available. We've dealt with one "Fast" DDoS attack on a website for a school district, and the answer was basically, "wait it out". After a couple hours the traffic subsided and the site became reachable again. That's a scenario where you need to rely on your host's ISP, or CloudFlare, to deal with mass attacks. Fortunately those are rare, and don't last long.
A slow attack takes far fewer resources -- but we've seen multiple attacks that target slow pages on a Drupal site, with basically everything changing with each request. This makes it so it never gets a page that's cached, forcing the server to do a lot of work, and it doesn't provide any patterns in its request that we can use to block. We've dealt with several attacks that have used thousands of unique IP addresses with several hundred unique "user agent" strings targeting tens of thousands of different URLs at a rate of several hundred requests per minute.
Fix - IPList blocking
These kinds of attacks usually have source IP addresses clustered around certain subnets. The sources tend to be commercial data centers, almost certainly not actual people sitting behind browsers. For extreme cases, we have blocked these subnets -- first by using IPTables rules like for a simple DDoS but covering entire network ranges, but more recently using IP lists published by other system administrators. https://iplists.firehol.org/ is the place to start - the firehol_level1 IP list is a starting point we've used, although we still ended up adding several dozen subnets actively being used in an attack.
Fix - Drupal ECA module
One site we manage has been hit by a bunch of these attacks. I turned to Claude AI for some assistance, providing some logs and looking for some other options. Claude managed to identify a few things I hadn't noticed. First of all, while there were hundreds of different user agents, they were all old -- nothing current. Secondly, the requests did not stick around to wait for a response -- Nginx logged the requests with a "499" code, "Client Closed Request". And third, there was a pattern to the requested URLs -- a couple specific query parameters and a specific count of query parameters.
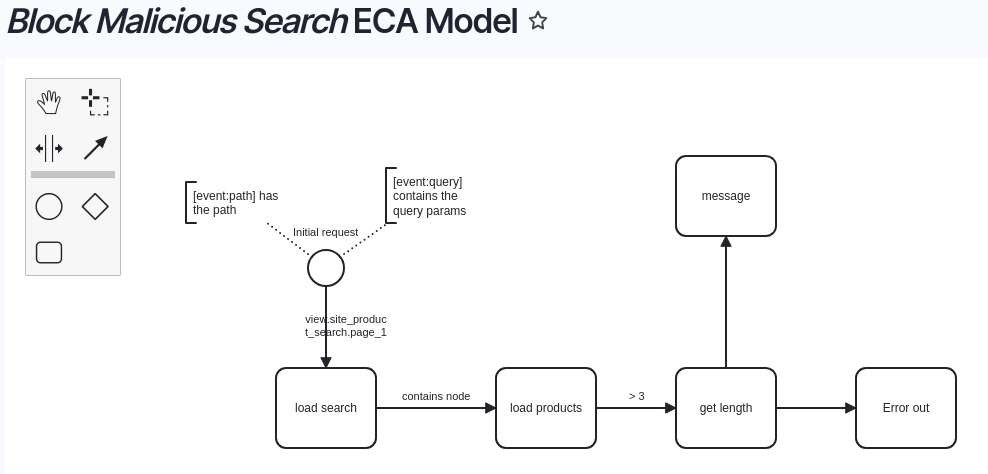
ECA is Drupal's "Events, Conditions, and Actions" module, and it's a no-code automation engine for Drupal that we have used for all sorts of different purposes. Based on the observations Claude helped us make, I created an ECA to detect the expensive search queries used in the attack, and if they matched the pattern, had ECA throw an exception before any of the expensive processing could take place.
When I created this model, ECA couldn't actually interrupt the request. I needed to create an action plugin to throw an "Access Denied" exception, which we then contributed back to the main ECA project.
Cause 9 - Too much legitimate traffic
Sometimes it feels like I'm alone shouting into the void, "You don't need more servers!" Kubernetes has taken over the DevOps world, and it's a tool I've never used. Its whole point is to automatically add containers across a bunch of hardware as needed, in response to changes in traffic and load levels.
There are of course many huge websites sites that take a lot of redundant servers to handle all the traffic they get. Your site is almost certainly not one of them. We've managed the hosting of hundreds of websites, including regional newsletter chains, school districts, community colleges, university departments, international aid organizations, huge associations, magazines, radio stations, and even a couple A-list rock bands. Not one of them needed multiple front-end servers or a load balancer to handle the load. We did have one incident early on for a small site that had a viral moment appearing on national news on all major networks -- at the time we didn't have beefy enough servers to handle that, but a similar incident today could be easily handled on a large instance with a good front-end cache. We did diagnose and fix a performance issue on a production database for one of those rock band sites, making it responsive again.
When a site is getting tons of traffic, the first step is to tune the server to maximize the throughput. That takes an understanding of some of the basics of how computers work -- RAM, CPU, I/O, along with throughput.
Fix - Maximize RAM utilization while avoiding swap
The most common bottleneck, and the first place to tune, is memory available for PHP. PHP is the main bottleneck for Drupal sites, especially for logged in users -- anonymous traffic can largely be cached, minimizing the need for more PHP. You have two knobs for tuning PHP -- the number of processes, and the maximum RAM each process can use. This is simple math. If the server has 16GB of RAM, and you need ~1GB for the operating system and web server, that means you can use at most 15GB of RAM. If your site errors out with PHP memory limits below 256M, that means you can run 60 PHP processes before running out of RAM (256M x 4 is roughly 1GB, 4 x 15 is 60). The more PHP processes the server has running, the more traffic it can handle.
So if you can reduce the memory per PHP process, you can add more processes -- but reduce it too far and Drupal will give you whitescreens and PHP memory errors. Make it too big and you can't run as many processes.
Make a change, and then watch memory utilization -- Linux likes to keep at least ~50M - ~60M free, so if you're getting close to that watch out -- if it runs out, the kernel will kill something, and you don't necessarily get to choose what. And that can lead to another outage.
The dmesg command will show the kernel logs, and you'll see an "OOM KIlled" message if the kernel killed something. You can add a swapfile if you're right on the edge -- this will prevent things from getting killed, but if it's used it will drastically start slowing things down as memory is swapped out to disk.
Fix - Provision more RAM/CPU
This is another reason we like using VPCs for hosting -- virtual servers can be resized, often even on the fly without shutting down (depending on the host). At worst, you might need to reboot. If you don't have enough RAM, an option is to just get a bigger server. If the server is CPU-bound, with all cores working at 100%, you definitely need more CPU. Most cloud hosts let you upgrade a VPC by simply logging into the hosting panel and picking a larger size.
Fix - Move stuff to other servers
While we don't care for load balancers, splitting up the various components needed to run a CMS makes a lot more sense. Our small sites run everything on one host -- Web server, PHP runtime, database server, sometimes even a Solr server and Redis. You can move each of those to a dedicated host, and offload a lot of processing if the site needs it.
Cloud hosts like Amazon Web Services (AWS) have managed offerings for many of these -- we often use their "Relational Database Service" for site databases, for example. We find RDS to make sites slightly slower and substantially more costly, but it also means you can restore to any individual minute within the past 48 hours - if daily backups are not often enough, RDS is a great solution. We've used ElastiCache for a dedicated Redis instance, moving that off the main host. And Solr is another server that can be moved to a dedicated host -- or you can use ElasticSearch.
Fix - Add a front-end cache
Is some story on the site going viral? Back in the day this was called being "Slashdotted", based on the common occurrence of stories reaching the front page of Slashdot taking down sites featured. Now we have all kinds of tools to handle this level of traffic.
My favorite right now is Nginx's fastcgi_cache. With this cache, Nginx automatically stashes pages that anonymous people visit into a fast cache, and when another visitor requests the same page, serves it from the cache instead of going back to PHP to fetch it. If you have this in place, instead of being able to handle ~60 simultaneous connections (in 15 GB of RAM, for your PHP limits), you can handle hundreds, possibly thousands. A cache of even 3 - 5 minutes can make it so the server can handle 100x as much traffic.
We now have a configuration in our Salt system that makes it easy to apply this on any site that needs it.
Other common options include Varnish, CloudFlare, or load balancers with a caching proxy server (which is essentially what Nginx is).
Fix - Add a back-end cache
If you have a lot of users who log in, front-end caches are useless -- personalization of pages make it so they can't be cached as a whole. This is where Drupal shines, with its extensive cache layers and systems. The problem is, out of the box, Drupal caches are all in the database, and the database can be huge. If you move the caching to an in-memory database, it vastly speeds up Drupal caching. Redis and Memcached are the main memory caches we've used with Drupal -- adding either makes a huge difference in site speed for any logged in users.
Fix - Tune the database
I'm not going to go into much detail here -- the main things to check for when it comes to the database are deadlocks, slow queries, queries without an index. EXPLAIN and learning about table cardinality can help you address the index issues -- but there's another dedicated job title for database administrators! Sometimes this can be a problem with the application and not so much the database -- doing large queries inside a big loop, for example.
Cause 10 - Out of disk space
This should probably get moved up -- this is probably the most frequent cause of outages on our watch. We now monitor disk usage and alert as they approach 100% usage -- but getting this right has been a problem, since if you deploy something it looks like the disk will fill in no time and set off all the alerts, when it's really a slow process with weird spikes. In short, this is one of the first things to check when diagnosing an outage -- is there available disk space on both the system and data disks?
Fix - clear up disk space
On our systems, Docker images can accumulate and use a lot of disk, as can unused packages on our older Ubuntu servers. Logs are another place that can grow, particularly database binary logs if there's a spike in traffic. Nix is very disk-hungry, and we're starting to use it even on non NixOS servers for PHP compatibility -- so our newer servers often need garbage collection and optimization -- nix-collect-garbage -d and nix store --optimize can free up a ton of space.
And if that's not enough, go out to the hosting panel and grow the disks as needed.
Cause 11 - Email delivery issues
While it's not necessarily related to the website being up, it does relate to availability in that it's something all our websites do -- send email. Even if it's just the occasional password reset. Email delivery is another whole article. For the most part, we've stopped trying to support mail sent directly through PHP, and we end up installing modules to configure SMTP delivery straight from the website to whatever email service the client uses.
Cause 12 - You've been hacked
Finally, the worst one -- because if an attacker has gained access to your web server, you don't just have an availability issue, you also have a confidentiality and possibly a data integrity issue too. A ransomware attack can encrypt your site and data so you can't access it. A malicious attacker can delete your site, and your backups if they can reach them. We had one client with another vendor delete the entire web server, not realizing that's what it was!
We noticed before the client did. Fortunately this "friendly fire" wasn't a big deal -- we just spun up a new server from the previous night's snapshots, which the vendor had left intact.
But if anything more malicious happens, everything changes. First of all, you'll need to do some forensics to determine the extent of the access, and how they broke in. There are so many places this might have happened -- if you don't know how the attacker broke in, recovering the site can lead to it just getting hacked again. You may have legal obligations to report the hack, to law enforcement and your customers. And you'll almost certainly suffer a hit to your reputation.
Those are issues for another day. Where it relates to availability, if you can't trust the environment, spin up a new one, and follow the steps above similar to addressing a hardware failure -- after closing whatever vulnerability let the attacker gain access in the first place.
You do have backups, right? And you have them somewhere the attacker can't reach?
If you have trouble keeping your Drupal or WordPress site available, reach out!
Add new comment